
 English
English Español
EspañolVisit us this year at,
One AI-Engine, four products
Exceptional performance for different industries

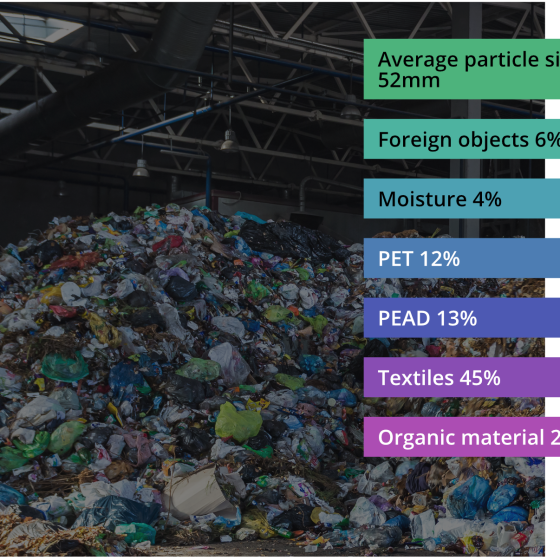


















What we do
Automate existing processes with computer vision. Our products are designed to handle manual tasks, saving our customers valuable time and resources.
With our products, companies can face challenges with confidence, knowing that their operations are optimized for their business.
By simplifying and automating these processes, we reduce not only the time spent on routine activities, but also the potential for error associated with manual workflows.
Explore Our Products
We understand the importance of implementing cutting-edge AI technology without disrupting your business operations. That’s why our AI-based products are designed to be effortlessly integrated into your existing workflows, allowing you to scale your operations.
Need a
custom solution?
Our advanced AI custom solutions can help you to tackle specific challenges and help your business progress.
Our Mission
Driven by AI technology, our mission is to empower businesses across industries, equipping them with the tools needed to thrive in today’s digital landscape
TARTAGLIA (con Nº de referencia TSI-100205-2021-11) está enmarcado dentro del programa Misiones de I+D en Inteligencia Artificial de la agenda España Digital 2025 y de la Estrategia Nacional de Inteligencia Artificial, y está financiado por la Unión Europea a través de los fondos NextGenerationEU. Las acciones realizadas se reportan al Ministerio para la Transformación Digital y de la Función Pública (Nº expediente MIA.2021.M02.0005), correspondiente a los fondos del Plan de Recuperación, Transformación y Resiliencia.

El proyecto SEPARA está subvencionado por el CDTI y ha sido apoyado por el Ministerio de Ciencia, Innovación y Universidades.

We provide Visual AI solutions to meet your business needs.