

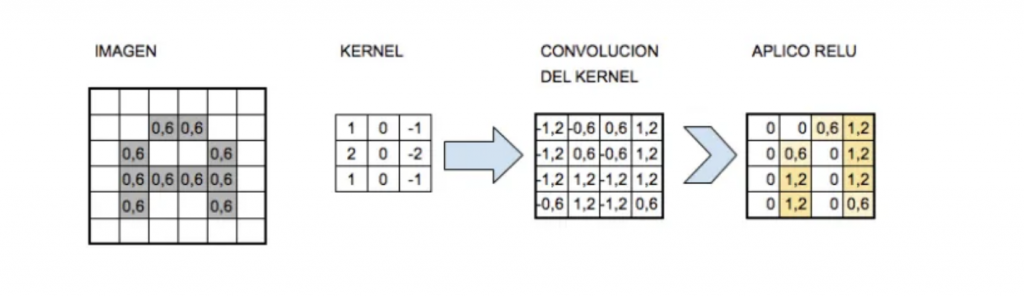
Si recordáis, en la primera parte de las CNN os contaba que era el kernel y como hacíamos la convolución (¿Que son las Redes Neuronales Convolucionales? Parte 1).
En este primer proceso se da un paso más tras la convolución del kernel y es la aplicación de una función de activación. En este caso se usa la función ReLu (Rectifier Linear Unit).
Pero… ¿Por qué se usa esta función con las CNN? pues es simple, cuando procesamos una imagen, cada capa de convolución debe capturar algún patrón en la imagen y pasarla a la siguiente capa de convolución. Los valores negativos no son importantes en el procesamiento de imágenes y se establecen en 0. Pero los valores positivos después de la convolución deben pasar a la siguiente capa. Es por eso que ReLu se está utilizando como una función de activación. Si utilizamos sigmoide o tanh, la información se pierde ya que ambas funciones modificarán las entradas a un rango muy cerrado.
Subsampling (Muestreo)
Ahora viene un paso en el que tomamos una muestra de las neuronas más representativas antes de hacer una nueva convolución.
¿Por qué aplicamos un muestreo?. Antes vimos que con una imagen blanco y negro de 28×28 pixels tenemos una primera capa de entrada de 784 neuronas y tras la primer convolución obtenemos una capa oculta de 25.088 neuronas (que realmente son nuestros 32 mapas de características de 28×28).
Si hiciéramos una nueva convolución a partir de esta capa, el número de neuronas de la próxima capa requeriría un poder computacional importante. Por ello y para reducir el tamaño de la próxima capa de neuronas hacemos un muestreo preservando las características más importantes que detectó cada filtro.
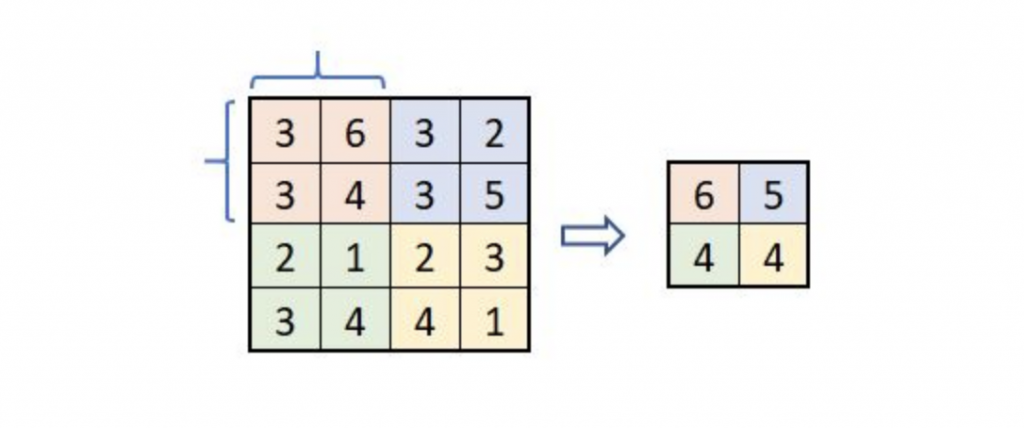
Subsampling con Max-Pooling
De todos los tipos de muestreo que existen, el Max-Pooling es el más usado.
¿Cómo lo hacemos? Recorremos cada una de las 32 imágenes de características obtenidas anteriormente de 28×28 px, de izquierda-derecha y arriba-abajo. En vez de ir pixel a pixel, tomaremos una matriz de 2×2, es decir, 4 pixels y nos iremos quedando con el valor más alto de esos 4 pixels.
Al estar usando una matriz de 2×2, la imagen resultante es reducida “a la mitad” y quedará de 14×14 pixels, así con las 32 imágenes. Ahora habremos pasado de 25.088 neuronas a 6272, las cuales son bastantes menos y que, en teoría, deberían seguir almacenando la información más importante para detectar características deseadas.
¿Y ahora qué? MÁS convoluciones
La primera convolución es capaz de detectar características primitivas como líneas o curvas. A medida que hagamos más capas con las convoluciones, los mapas de características serán capaces de reconocer formas más complejas y el conjunto total de capas de convoluciones podrá “ver” las imágenes.
La segunda convolución y sucesivas tendrán este esquema:
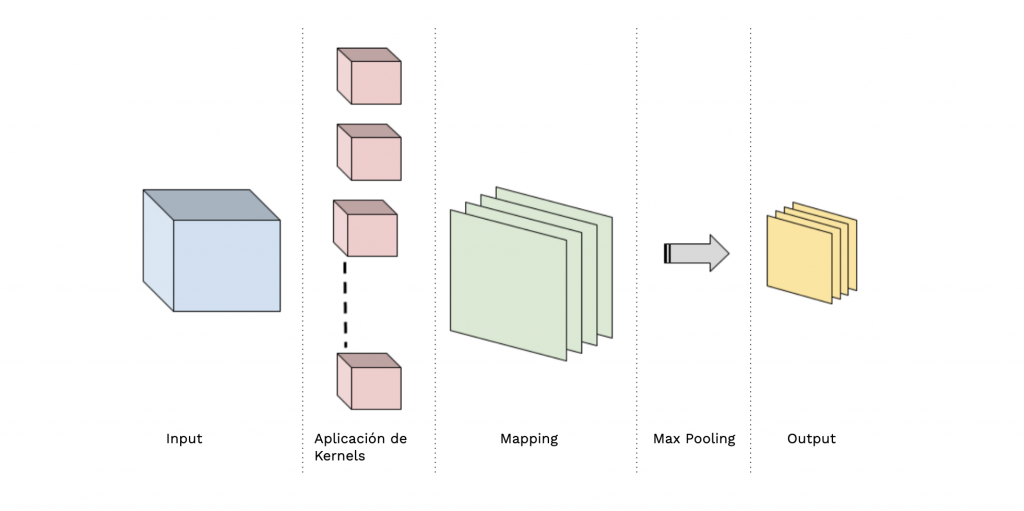
La segunda convolución tendrá un input de 14×14 pixels (32 mapas), se le aplica 64 filtros de 3×3 píxeles obteniendo un feature mapping de 14×14 pixels (64 mapas), se le hace un max-pooling de 2×2 a los 64 mapas y acabamos con un output de 64 mapas de 7×7 píxeles.
En cuanto a la tercera:
- Input: 64 mapas (imágenes) de 7×7.
- Kernels: 128 filtros de 3×3.
- Feature Mapping: 7×7 y 128 mapas de características.
- Max-Pooling: 2×2 pixels.
- Output: 128 mapas de 3×3.
Y así sucesivamente hasta realizar n convoluciones.
Desenlace
Cuando ya se han realizado todas las convoluciones necesarias, hay que conectar el output de la última convolución a una red neuronal “tradicional”.
A esta nueva capa oculta “tradicional”, le aplicamos una función llamada Softmax que conecta con la capa de salida final que tendrá la cantidad de neuronas correspondientes con los elementos que estamos clasificando. Es decir, si estamos intentando clasificar perros, gatos, cebras y jirafas, tendrá 4 neuronas.
Las salidas al momento del entrenamiento tendrán el formato conocido como “one-hot-encoding” en el que para perros, gatos, cebras y jirafas será: [1,0, 0, 0], [0, 1, 0,0], [0, 0, 1,0] y [0, 0, 0,1], si fuesen tres elementos sería [1,0,0]; [0,1,0];[0,0,1] y con dos elementos [1,0] y [0,1].
Y la función de Softmax se encarga de pasar la probabilidad (entre 0 y 1) a las neuronas de salida. Por ejemplo, para la clasificación de los animales podríamos tener este resultado [0.2 0.2 0.35 0.25] nos indica 20% probabilidades de que sea perro, 20% de que sea gato, 35% de que sea cebra y 25% de que sea jirafa.
La guinda del pastel
¿Cómo acaba aprendiendo a “ver” esta red neuronal?, pues gracias al Backpropagation.
El proceso es similar al de las redes tradicionales en las que tenemos una entrada y una salida esperada (aprendizaje supervisado) y mediante backpropagation mejoramos el valor de los pesos de las interconexiones entre capas de neuronas, a medida que iteramos esos pesos se ajustan hasta ser óptimos.
En el caso de las CNN se debe ajustar el valor de los pesos de los distintos kernels. Esto es una gran ventaja al momento del aprendizaje pues como vimos, cada kernel es de un tamaño reducido. Como hemos visto en el ejemplo de este artículo, para la primera convolución el tamaño del kernel es de 3×3, es decir 9 parámetros a ajustar en 32 imágenes, 288 parámetros en total. En una red tradicional con dos capas de neuronas tendríamos una capa con 748 y otra con 6272 con todas ellas interconectadas por lo que habría que equivaldría a tener que entrenar y ajustar más de 4,5 millones de pesos y solo de una capa.
Tal y como queda demostrado, las CNN son toda una ventaja que nos ahorra tiempo y recursos, sin olvidar lo increíble que es la “imitación” del cerebro humano.
Por Alejandro Delgado – Lead Data Scientist en Pixelabs.
Share your thoughts
No Comments
Sorry, the comment form is closed at this time.