

Machine Learning (I)
Machine Learning es una disciplina científica del ámbito de la Inteligencia Artificial que crea sistemas que aprenden automáticamente. Aprender en este contexto quiere decir identificar patrones complejos en millones de datos. La máquina que realmente aprende es un algoritmo que revisa los datos y es capaz de predecir comportamientos futuros. Automáticamente, también en este contexto, implica que estos sistemas se mejoran de forma autónoma con el tiempo, sin intervención humana. Veamos cuales son estos algoritmos.
Los algoritmos de aprendizaje automático se pueden dividir en tres grandes categorías: aprendizaje supervisado, aprendizaje no supervisado y aprendizaje por refuerzo. El aprendizaje supervisado es útil en los casos en que una propiedad (etiqueta) está disponible para un determinado conjunto de datos (conjunto de formación), pero debe predecirse para otras instancias. El aprendizaje no supervisado es útil en los casos en que el desafío consiste en descubrir relaciones implícitas en un conjunto de datos no etiquetado (los elementos no están asignados previamente). El aprendizaje por refuerzo cae entre estos dos extremos: hay alguna forma de retroalimentación disponible para cada paso o acción predictiva, pero no hay etiqueta precisa o mensaje de error.
En este artículo solo veremos los algoritmos más comunes en Aprendizaje Supervisado, dejando así para las siguientes publicaciones los algoritmos de aprendizaje por refuerzo y aprendizaje no supervisado.
Aprendizaje Supervisado
Dentro de la categoría de Aprendizaje Supervisado (Supervised Learning), tenemos dos clases de problemas: Regresión y Clasificación.
Regresión es cuando queremos predecir un resultado que varía en un rango continuo. Por ejemplo, dada la foto de una persona determinar su edad. Otro ejemplo podría ser dadas las características de una casa que está en venta, predecir cuál es el precio adecuado de venta. Clasificación es para predecir resultados que son discretos. Por ejemplo, dado un paciente con un tumor, determinar si el tumor es maligno o no. Otro problema que entra en esta categoría es por ejemplo, dada la imagen de un número de un dígito escrito a mano, identificar de qué dígito se trata.
Dentro de esta categoría podemos encontrar alguno de los siguientes algoritmos:
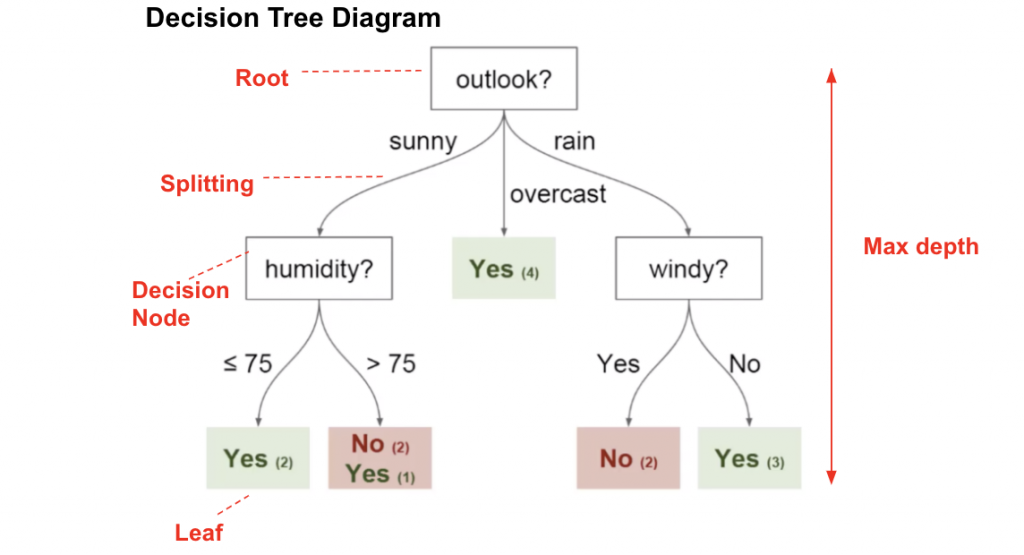
1. Árboles de decisión: Un árbol de decisiones es una herramienta de apoyo a la decisión que utiliza un gráfico o un modelo similar a un árbol de decisiones y sus posibles consecuencias, incluidos los resultados de eventos fortuitos, los costos de recursos y la utilidad. Presentan una apariencia como esta:
Desde el punto de vista de la toma de decisiones empresariales, un árbol de decisiones es el número mínimo de preguntas sí / no que uno tiene que hacer, para evaluar la probabilidad de tomar una decisión correcta, la mayoría del tiempo. Este método le permite abordar el problema de una manera estructurada y sistemática para llegar a una conclusión lógica.
2. Clasificación Naïve Bayes: Naïve Bayes es un modelo de predicción basado en la probabilidad Bayesiana. El modelo es muy simple, pero poderoso, en cuanto que es resultado directo de los datos y su tratamiento con simple estadística bayesiana de la probabilidad condicionada. Hay que tener en cuenta que se asume, por simplificación, que las variables son todas sucesos independientes.
Si tenéis curiosidad por cómo funciona este algoritmo, os recomiendo el siguiente enlace donde además se explica cómo se haría en Python → Algoritmo del Clasificador Naive Baye
3. Ordinary Least Squares Regression (Regresión por mínimo cuadrados): Si has estado en contacto con la estadística, probablemente hayas oído hablar de regresión lineal antes. Ordinary Least Squares Regression es un método para realizar la regresión lineal. Se puede pensar en la regresión lineal como la tarea de ajustar una línea recta a través de un conjunto de puntos. Hay varias estrategias posibles para hacer esto, y la estrategia de «mínimos cuadrados ordinarios» va así: puede dibujar una línea y luego, para cada uno de los puntos de datos, medir la distancia vertical entre el punto y la línea y sumarlos; La línea ajustada sería aquella en la que esta suma de distancias sea lo más pequeña posible.
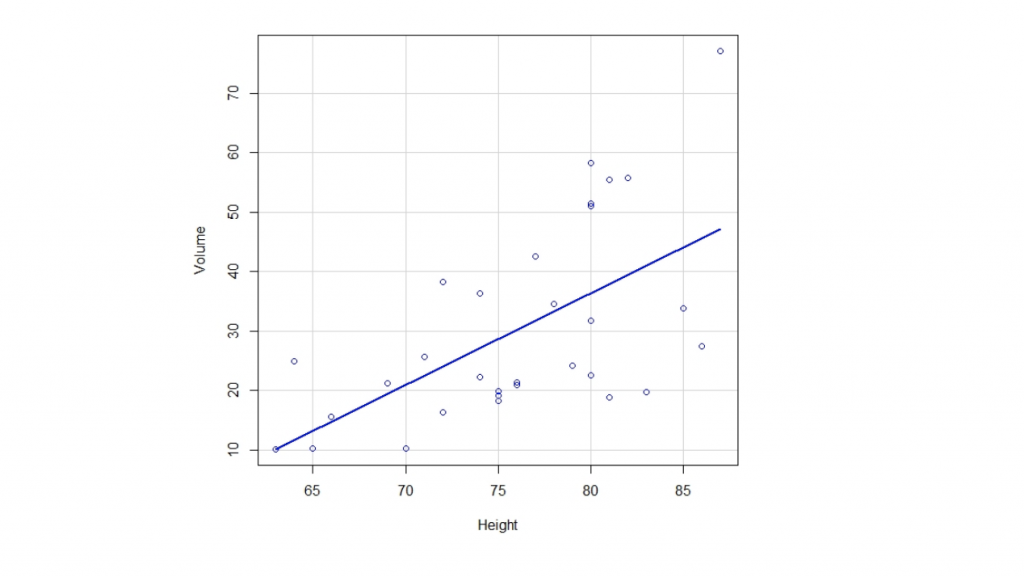
Linear se refiere al tipo de modelo que está utilizando para ajustar los datos, mientras que los mínimos cuadrados se refieren al tipo de métrica de error que está minimizando.
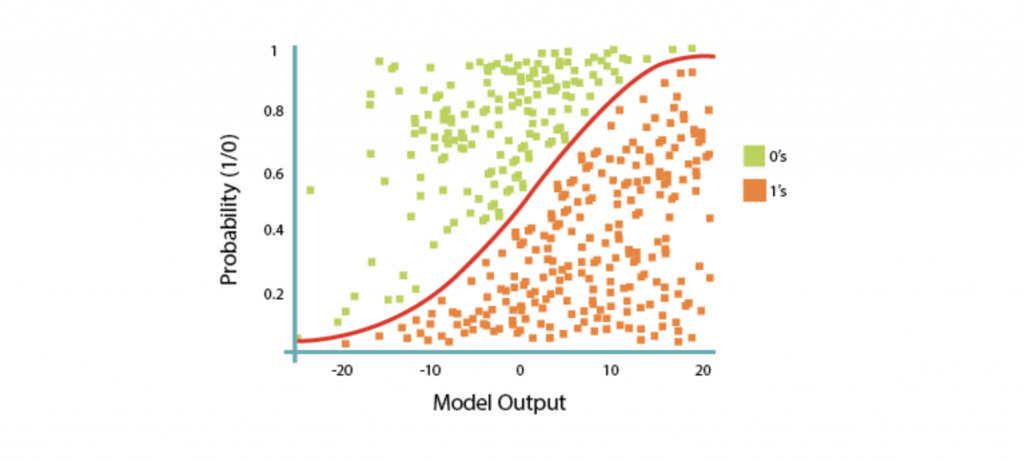
4. Regresión Logística: La regresión logística es un procedimiento cuantitativo de gran utilidad para problemas donde la variable dependiente toma valores en un conjunto finito. Su uso se impone de manera creciente desde la década de los 80 debido a las facilidades computacionales con que se cuenta desde entonces.
La regresión logística puede utilizarse como método descriptivo cuando se desea estudiar desde una perspectiva epidemiológica la aparición de un determinado evento en un grupo de individuos, por ejemplo:
- Los pacientes de una determinada enfermedad desarrollan un cierto signo propio de ésta.
- Los niños dejan la lactancia materna exclusiva.
- El fallecimiento de individuos de una cohorte.
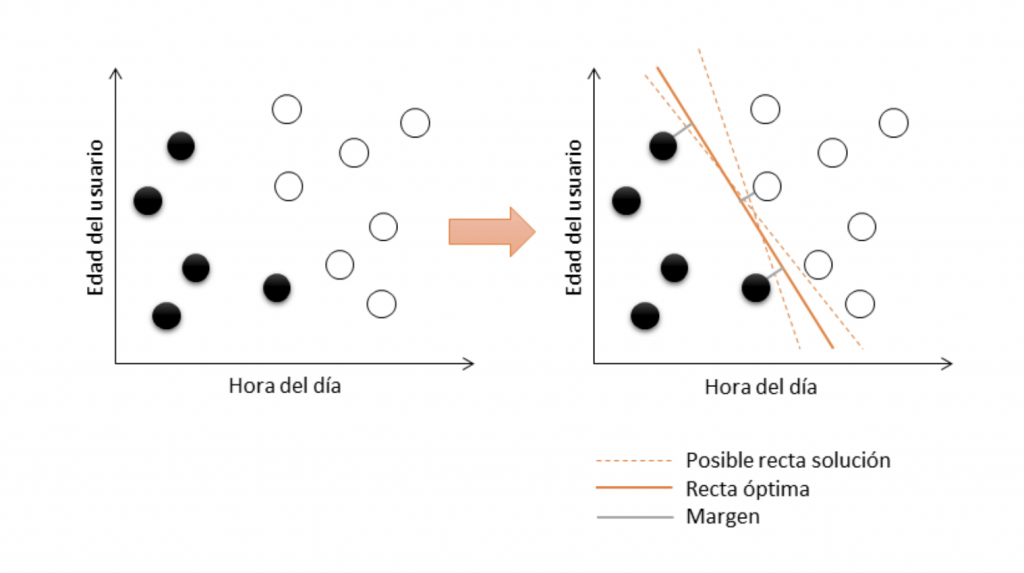
5. Support Vector Machines: es un algoritmo de aprendizaje supervisado que se utiliza en muchos problemas de clasificación y regresión, incluidas aplicaciones médicas de procesamiento de señales, procesamiento del lenguaje natural y reconocimiento de imágenes y voz. El objetivo del algoritmo SVM es encontrar un hiperplano que separe de la mejor forma posible dos clases diferentes de puntos de datos. “De la mejor forma posible” implica el hiperplano con el margen más amplio entre las dos clases, representado por los signos más y menos en la siguiente figura. El margen se define como la anchura máxima de la región paralela al hiperplano que no tiene puntos de datos interiores. El algoritmo sólo puede encontrar este hiperplano en problemas que permiten separación lineal; en la mayoría de los problemas prácticos, el algoritmo maximiza el margen flexible permitiendo un pequeño número de clasificaciones erróneas.
Por ejemplo:
Imaginemos que buscamos encontrar qué tipo de usuario tiene más probabilidad de hacer clic en un determinado banner. Está claro que esta decisión implica varias variables a tener en cuenta: no solo de las características del propio usuario, sino también podremos considerar su región geográfica, la tecnología empleada, día/hora en que se encuentra con el banner, etc. Si solo dos de estas variables fueran determinantes, podríamos encontrarnos en una situación similar a la de la imagen, donde el círculo negro identifica que el usuario hace clic, y el blanco que no. Con SVM podemos obtener la “superficie óptima” que delimitará el comportamiento clic – no clic de un usuario:
¡Y hasta aquí los más comunes!, aunque hay muchísimos más que pueden usarse.
Por Alejandro Delgado – Lead Data Scientist en Pixelabs.
Share your thoughts
No Comments
Sorry, the comment form is closed at this time.