

Machine Learning (II)
Hoy vamos a continuar con los algoritmos más usados en Machine Learning, concretamente los algoritmos de Aprendizaje no Supervisado.
Recordando un poco el anterior artículo, los algoritmos de Aprendizaje no Supervisados infieren patrones de un conjunto de datos sin referencia a resultados conocidos o etiquetados. A diferencia del Aprendizaje Supervisado, los métodos de Aprendizaje no Supervisado no se pueden aplicar directamente a un problema de regresión o clasificación porque no tiene idea de cuáles pueden ser los valores de los datos de salida, lo que hace imposible que entrene el algoritmo de la forma en que lo haría normalmente. En cambio, el aprendizaje sin supervisión puede utilizarse para descubrir la estructura subyacente de los datos.
Aprendizaje No Supervisado
Los algoritmos de Aprendizaje no Supervisados te permiten realizar tareas con datos no etiquetados a diferencia del Aprendizaje Supervisado. Sin embargo, el aprendizaje sin supervisión puede ser más impredecible en comparación con otros métodos de aprendizaje.
Estos algoritmos se utilizan para agrupar los datos según sus similitudes y patrones distintos en el conjunto de datos. El término “no supervisado” se refiere al hecho de que el algoritmo no está guiado como el algoritmo de Aprendizaje Supervisado.
La manera más fácil de entender esto es con un ejemplo: tenemos un bebe y su perro. El bebe conoce e identifica a su perro. Unas semanas más tarde, un amigo de la familia trae un perro y trata de jugar con la bebé. La bebé no ha visto a este perro antes, pero reconoce muchos rasgos de él, 2 orejas, 2 ojos, caminar sobre 4 patas, son como su mascota. Ella identifica al nuevo animal con un perro. Este ejemplo se trata de un aprendizaje sin supervisión, en el que no se le enseña, sino que se aprende a partir de los datos, en este caso, los datos sobre un perro.
Los algoritmos de aprendizaje no supervisado se dividen en dos grupos:
Algoritmos Clustering:
El Clustering (o algoritmo de agrupamiento) consiste en agrupar una serie de vectores seg ́un un criterio en grupos o clusters. Generalmente el criterio suele ser la similitud por lo que diremos que agrupa los vectores similares en grupos.
Algunos de los algoritmos más usados son:
K-Means
Agrupa objetos en k grupos basándose en sus características. El agrupamiento se realiza minimizando la suma de distancias entre cada objeto y el centroide de su grupo o cluster. Se suele usar la distancia cuadrática.
El algoritmo consta de tres pasos:
- Inicialización: una vez escogido el número de grupos, k, se establecen k centroides en el espacio de los datos, por ejemplo, escogiendo aleatoriamente.
- Asignación objetos a los centroides: cada objeto de los datos es asignado a su centroide más cercano.
- Actualización centroides: se actualiza la posición del centroide de cada grupo tomando como nuevo centroide la posición del promedio de los objetos pertenecientes a dicho grupo.
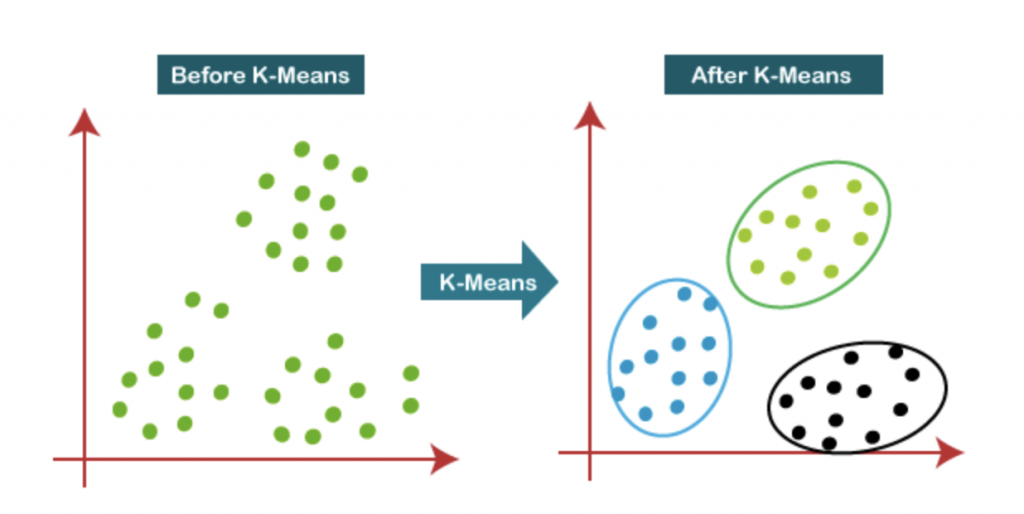
Mean Shift:
La agrupación Mean Shift es un algoritmo basado en ventanas deslizantes que intenta encontrar áreas densas de puntos de datos. Es un algoritmo basado en el centroide, lo que significa que el objetivo es localizar los puntos centrales de cada clúster, lo que funciona actualizando a los candidatos para que los puntos centrales sean la media de los puntos dentro de la ventana deslizante.
Estas ventanas candidatas son filtradas en una etapa de post procesamiento para eliminar los duplicados cercanos, formando el conjunto final de puntos centrales y sus correspondientes grupos.
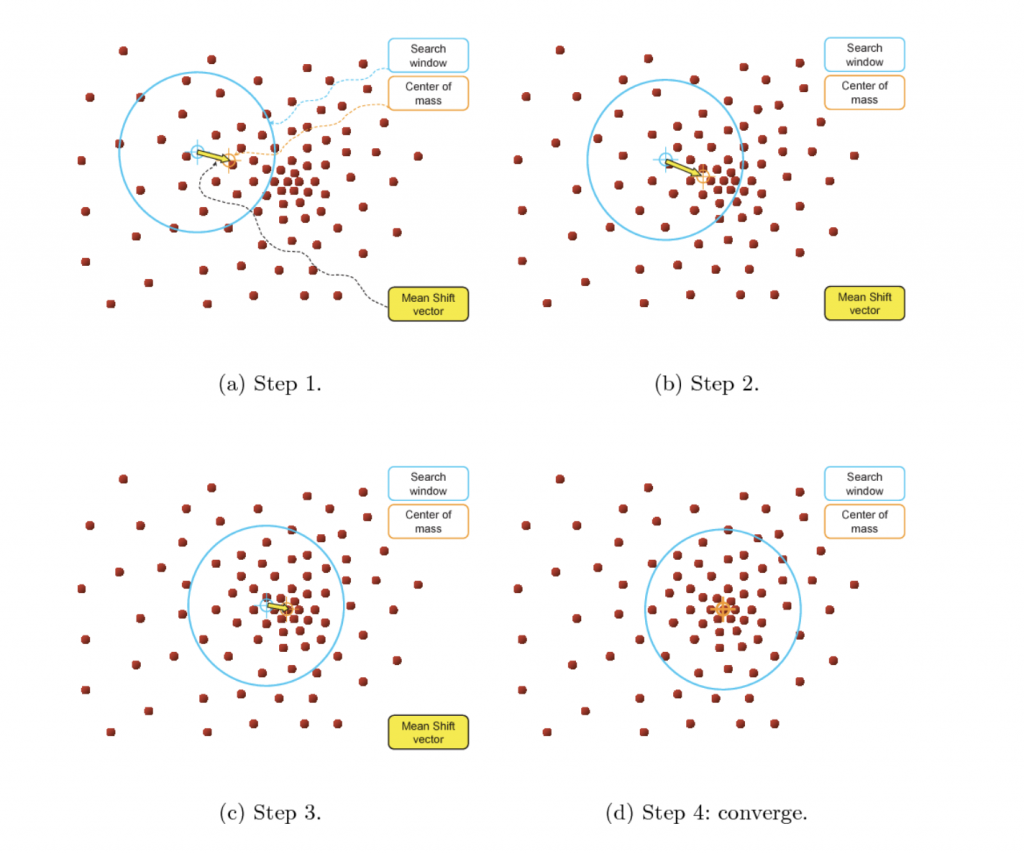
- Para explicar el agrupamiento Mean Shift consideremos un conjunto de datos en un espacio bidimensional. Comenzamos con una ventana circular deslizante centrada en el punto C, seleccionada aleatoriamente, y con el radio r como núcleo. Mean Shift es un algoritmo de escalada de colinas que implica el desplazamiento iterativo de este núcleo a una región de mayor densidad en cada paso hasta la convergencia.
- En cada iteración, la ventana deslizante se desplaza hacia regiones de mayor densidad desplazando el punto central a la media de los puntos dentro de la ventana. La densidad dentro de la ventana corredera es proporcional al número de puntos dentro de ella. Naturalmente, al cambiar a la media de los puntos en la ventana, gradualmente se moverá hacia áreas de mayor densidad de puntos.
- Seguimos desplazando la ventana corrediza de acuerdo con la media hasta que no hay dirección en la que un desplazamiento pueda acomodar más puntos dentro del núcleo.
- Este proceso de los pasos 1 al 3 se realiza con muchas ventanas hasta que todos los puntos se encuentran dentro de una ventana. Cuando se superponen varias ventanas, se conserva la ventana que contiene la mayor cantidad de puntos. A continuación, los puntos de datos se agrupan según la ventana deslizante en la que residen.
A diferencia de la agrupación K Means, no es necesario seleccionar el número de clústeres, ya que el desplazamiento medio lo descubre automáticamente. Es una gran ventaja. El hecho de que los clustering converjan hacia los puntos de máxima densidad también es muy deseable, ya que es bastante intuitivo de entender y encaja bien en un sentido naturalmente basado en datos. El inconveniente es que la selección del tamaño/radio “r” de la ventana puede ser no trivial.
Si quieres saber más sobre estos algoritmos te recomiendo este enlace.
Algoritmos de reducción de dimensionalidad de datos:
Los métodos de reducción de dimensionalidad son algoritmos que mapean el conjunto de los datos a subespacios derivados del espacio original, de menor dimensión, que permiten hacer una descripción de los datos a un menor costo.
Las razones por las que nos interesa reducir la dimensionalidad son varias:
- Porque interesa identificar y eliminar las variables irrelevantes.
- Porque no siempre el mejor modelo es el que más variables tiene en cuenta.
- Porque se mejora el rendimiento computacional, lo que se traduce en un ahorro en coste y tiempo.
- Porque se reduce la complejidad, lo que lleva a facilitar la comprensión del modelo y sus resultados.
Hay muchos algoritmos y técnicas para reducir la dimensionalidad, aquí váis a ver dos de ellos pero si queréis saber más no dudéis en entrar en este enlace.
- Selección de variables:
Un conjunto de variables óptimo para un conjunto de datos será el que contenga las variables más significativas del conjunto de datos original. Para seleccionar las variables se siguen diferentes criterios:
Dependencia o correlación. Por ejemplo, para un modelo de predicción de cáncer en individuos humanos, el conjunto de datos con el que se trabaje probablemente contenga variables como la edad, la existencia de cáncer en otros miembros de la familia, si es fumador o no… Pero no variables como el color de los ojos.
Ya sea por conocimiento en el campo o por lógica, podemos intuir cuáles son las variables más significativas. Pero no siempre podemos estar seguros de que el color de los ojos no influye en la probabilidad de padecer cáncer o quizá no queramos arriesgarnos a hacer tal afirmación.
Otro criterio es el de la consistencia. Puede ser que tengamos variables redundantes en nuestro conjunto que tuvieran una correlación entre ellas suficientemente fuerte como para que no merezca la pena tener las dos. Por ejemplo, siguiendo con el ejemplo de predicción de cáncer, quizá teniendo la variable de capacidad pulmonar, no merece la pena tener también la variable que indica si es fumador o no, ya que puede que esta última esté, de una forma u otra, ya recogida en la primera. La mejor forma de verlo es comprobarlo con métodos matemáticos.
- Análisis de componentes principales:
La técnica de análisis de componentes principales requiere unos conocimientos avanzados de matemáticas que no vamos a explicar pero que tampoco os harán falta para entender el concepto.
La idea básicamente es construir una dimensión (o variable) nueva a partir de la fusión de dos ya existentes. Vamos a ver un ejemplo con variables geográficas porque es más fácil de visualizar, pero se puede aplicar a cualquier tipo de variables, aunque sea más abstracto.
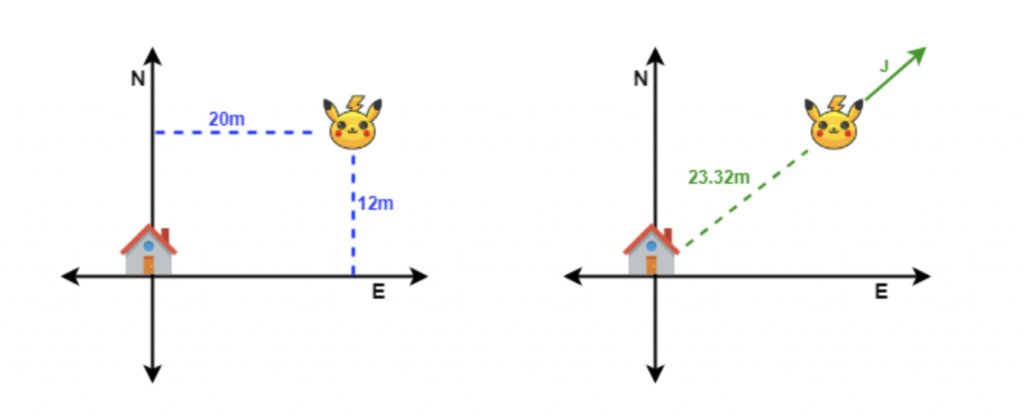
Vivimos en un punto del mapa, que tendremos como referencia, y observamos que hay un Pikachu a 12 m al Norte y a 20 m al Este. Estamos usando dos variables para describir dónde está el Pikachu, pero ¿podríamos combinarlas para así usar solo una variable?
Si nos inventamos nuestra propia coordenada J, que sería una combinación de la coordenada N y de la coordenada E, podemos describir en qué posición se encuentra el Pikachu con tan solo una variable. Habremos combinado dos dimensiones para crear una ficticia en su lugar.
Cuando solo tenemos un elemento es muy fácil. Cuando hay varios, debemos tener en cuenta la correlación entre las variables a fusionar, ya que a menor correlación, es más la información que se pierde.
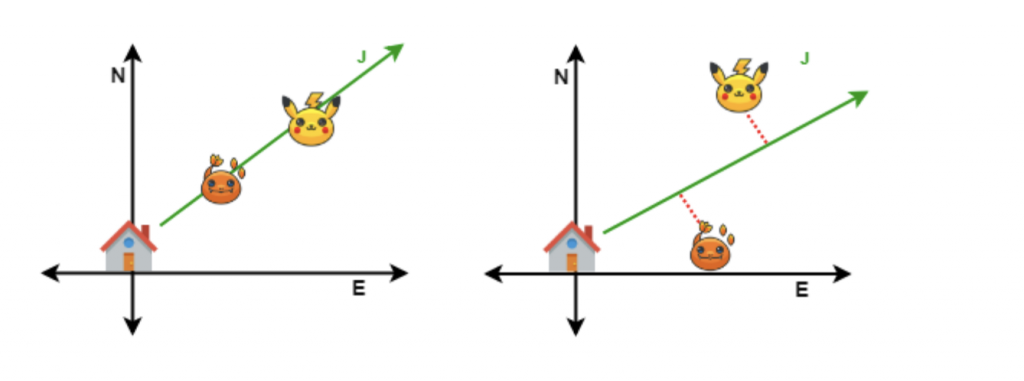
En nuestro ejemplo, N y E están correlacionadas cuando los elementos están alineados, ya que se puede trazar una línea recta pasando por todos sin mucho error. En cambio, cuando los elementos no están alineados (imagen de la derecha), la nueva dimensión J ya no representa a Pikachu ni a Charmander.
Por Alejandro Delgado – Lead Data Scientist en Pixelabs.
Share your thoughts
No Comments
Sorry, the comment form is closed at this time.