

Gran parte de la revolución que se ha vivido en los últimos años en el campo del Deep Learning ha sido gracias a la visión por ordenador o visión artificial y en especial al desarrollo de unas redes neuronales que están especializadas en trabajar con imágenes, las CNN (Convolutional Neural Networks).
La importancia de estas redes viene de su capacidad para poder descifrar los patrones más complejos en datasets masivos de imágenes, asemejándose a la forma en la que lo hace el ojo humano.
En Pixelabs son una gran herramienta para todos nuestros proyectos de visión y os vamos a contar un poco como funcionan.
En esta primera parte solo llegaremos hasta la aplicación de los filtros.
Semejanzas con el cerebro humano
En 1959, Hubel y Wiesel tuvieron un papel importante en la comprensión del funcionamiento de la corteza visual, particularmente las células responsables de la selectividad de orientación y detección de bordes en los estímulos visuales dentro de la corteza visual primaria.
Se identificaron dos tipos de células debido a que tienen campos receptivos alargados, lo que permite una mejor respuesta a los estímulos visuales alargados como bordes o líneas. Estás células se denominaron células simples y células complejas.
Las células simples tienen regiones excitadoras e inhibidoras, ambas forman patrones elementales alargados en una dirección, posición y tamaño en particular en cada célula. Si un estímulo visual llega a la célula con la misma orientación y posición, de tal manera que ésta se alinea perfectamente con los patrones creados por las regiones excitadoras y al mismo tiempo se evita activar las regiones inhibitorias, la célula es activada y emite una señal.
Las células complejas operan de una manera similar. Como las células simples, éstas tienen una orientación particular sobre la cual son sensibles. Sin embargo, éstas no tienen sensibilidad a la posición. Por ello, un estímulo visual necesita llegar únicamente en la orientación correcta para que esta célula sea activada.
De esta forma, las redes neuronales convolucionales consisten en múltiples capas de filtros convolucionales de una o más dimensiones. Después de cada capa, por lo general se añade una función para realizar un mapeo causal no-lineal. Las primeras capas pueden detectar líneas, curvas y así se van especializando hasta poder reconocer formas complejas como un rostro, siluetas, etc.
Luego hay una reducción por muestreo y al final tendremos neuronas de perceptrón más sencillas para realizar la clasificación final sobre las características extraídas.
La fase de extracción de características se asemeja al proceso estimulante en las células de la corteza visual. Esta fase se compone de capas alternas de neuronas convolucionales y neuronas de reducción de muestreo. Según progresan los datos a lo largo de esta fase, se disminuye su dimensionalidad, siendo las neuronas en capas lejanas mucho menos sensibles a perturbaciones en los datos de entrada, pero al mismo tiempo siendo estas activadas por características cada vez más complejas.
CNN en acción
Pixeles y Neuronas
La red neuronal toma como entrada los píxeles de una imagen. Si tenemos una imagen con apenas 28×28 píxeles de alto y ancho, eso equivale a 784 neuronas. Y eso es si sólo tenemos 1 color (escala de grises). Si tuviéramos una imagen a color, necesitaríamos 3 canales (red, green, blue) y entonces usamos 28x28x3 = 2352 neuronas de entrada. Esa es nuestra capa de entrada.
Pre-Procesamiento
Antes es necesario normalizar los datos, es decir que nuestros píxeles que ahora tienen valores entre 0 y 255, tengan valores entre 0 y 1, podemos lograrlo dividiendo cada uno de los píxeles al valor más alto que estos tienen es decir 255.
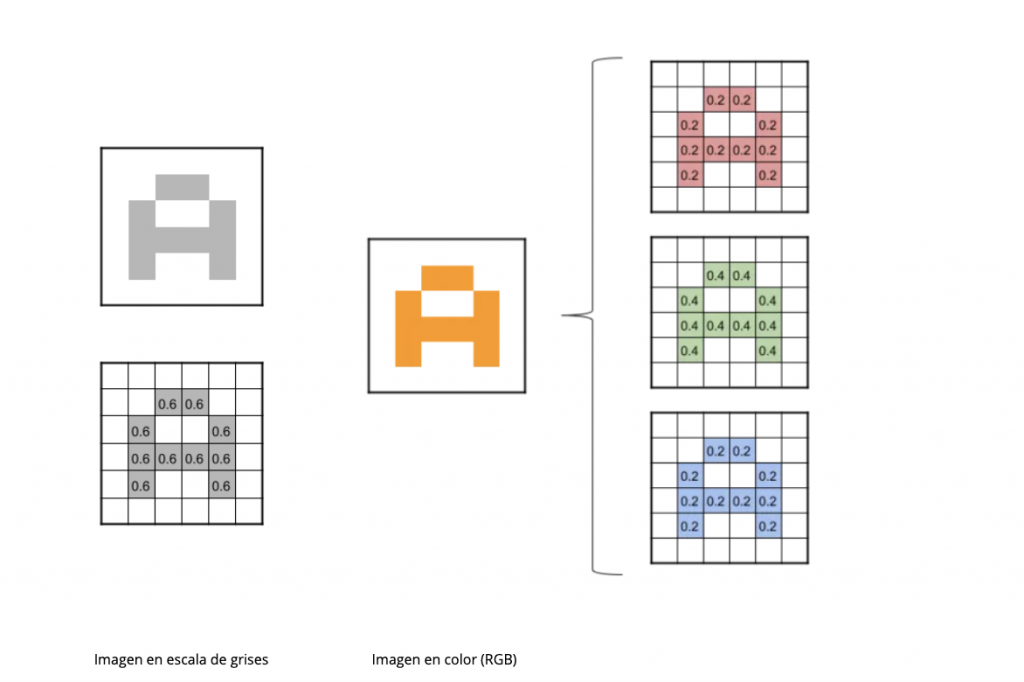
Fuentes imagen: Imagen en color; Imagen en escala de grises
El Kernel
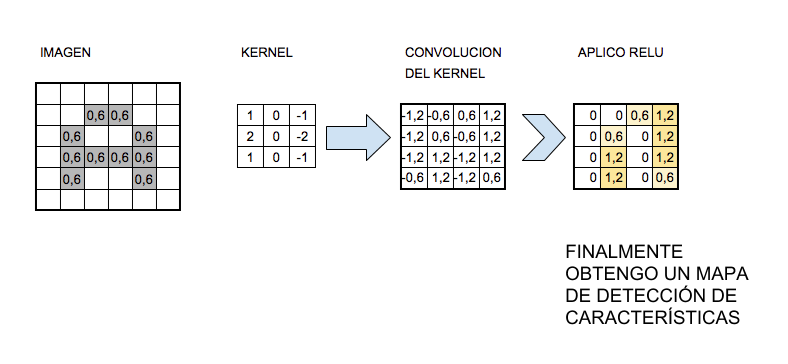
El kernel en las redes convolucionales se considera como el filtro que se aplica a una imagen para extraer ciertas características importantes o patrones de esta.
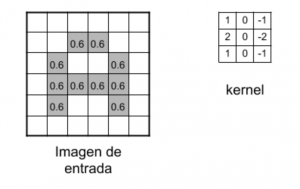
Por ejemplo si tenemos una imagen como la siguiente:

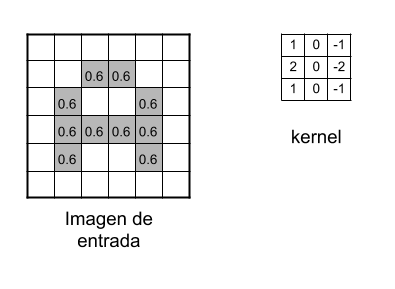
Aplicando el filtro o kernel se mostrará de la siguiente forma:

Entre las características importantes para lo que sirve el kernel son detectar bordes, enfoque, desenfoque, entre otros. Esto se logra al realizar la convolución entre la imagen y el kernel.
{kind=link}
Convolución
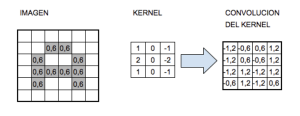
El “procesado distintivo” de las CNN, las convoluciones. Estas consisten en tomar grupos de píxeles cercanos de la imagen de entrada e ir operando matemáticamente (producto escalar) contra una pequeña matriz (Kernel).
Supongamos un kernel de tamaño 3×3 pixels, este “recorre” todas las neuronas de entrada (de izquierda-derecha, de arriba-abajo) y genera una nueva matriz de salida, que en definitiva será nuestra nueva capa de neuronas ocultas.
Si la imagen fuera a color, el kernel realmente sería de 3x3x3 es decir: un filtro con 3 kernels de 3×3; luego esos 3 filtros se suman y conformarán 1 salida.
Realmente no aplicaremos un sólo kernel, si no que tendremos muchos kernel (filtros). Por ejemplo, en esta primer convolución podríamos tener 32 filtros, con lo cual realmente obtendremos 32 matrices de salida (este conjunto se conoce como feature mapping, cada una de 28x28x1 dando un total del 25.088 neuronas para nuestra primera capa oculta de neuronas. Y esto solo para una imagen cuadrada de apenas 28 pixeles…

A medida que vamos desplazando el kernel vamos obteniendo una nueva imagen “filtrada” por el kernel. En esta primera convolución y siguiendo con el ejemplo anterior, es como si tuviéramos 32 “imágenes” filtradas nuevas. Estas imágenes nuevas están “dibujando” ciertas características de la imagen original. Esto ayudará en el futuro a poder distinguir un objeto de otro.
{kind=link}
¿Esto es todo? Pues como hemos apuntado al inicio de este artículo, no. Esto no es todo, aún nos quedan un par de procesos por delante que explicaremos en la próxima publicación.
Por Alejandro Delgado – Lead Data Scientist en Pixelabs.
Share your thoughts
No Comments
Sorry, the comment form is closed at this time.